

Neuro-sama 是一个完全由 AI 驱动的虚拟主播。没有真人在背后配音,没有动捕演员。Twitch 上那两万多个活人观众,面对的就是一堆代码。

我最早注意到她是在 2023 年。当时她已经因为说了一句否认 Holocaust 的话被 Twitch 封了两周,后来又因为粉丝拱火吃了第二次封禁。一个 AI 主播能被封号,这本身就挺离谱的。说明她不是照着脚本念的。
后来我认真看了她的技术细节,发现这套东西远比想象中有意思。一个人单枪匹马搭出来的自治系统,涵盖了 LLM 微调、TTS 管道、视觉输入、多 agent 协作,也没有用任何现成的 agent 框架。全是手搓的。
先是一个 osu! 外挂#
Neuro-sama 最开始跟"聊天"没有任何关系。
2018 年,化名 Vedal 的英国程序员训练了一个神经网络来打音游 osu!。模型把游戏画面压缩成 80×60 的灰度图,从中提取谱面节奏,预测鼠标点击时机。效果怎么样呢?人类顶尖选手打不过它。如果你没玩过 osu!,这差不多等于用机器学习写了个外挂。
2021 年 Vedal 冒出个念头:能不能给这个 bot 安个嘴?项目最初叫 “Airis”(AI + iris),后来因为跟 hololive 的 VTuber IRyS 撞名,Vedal 翻出了 osu! 时代的旧品牌 “Neuro-sama” 继续用。
2022 年 3 月两个项目合并,12 月 19 日在 Twitch 出道。起步阶段的对话靠 GPT-3 API 驱动。Vedal 自己在 Bloomberg 采访里确认过这个。
底层架构#
别看 Neuro 在屏幕上就是个会动的二次元少女,底下跑了好几套独立系统。
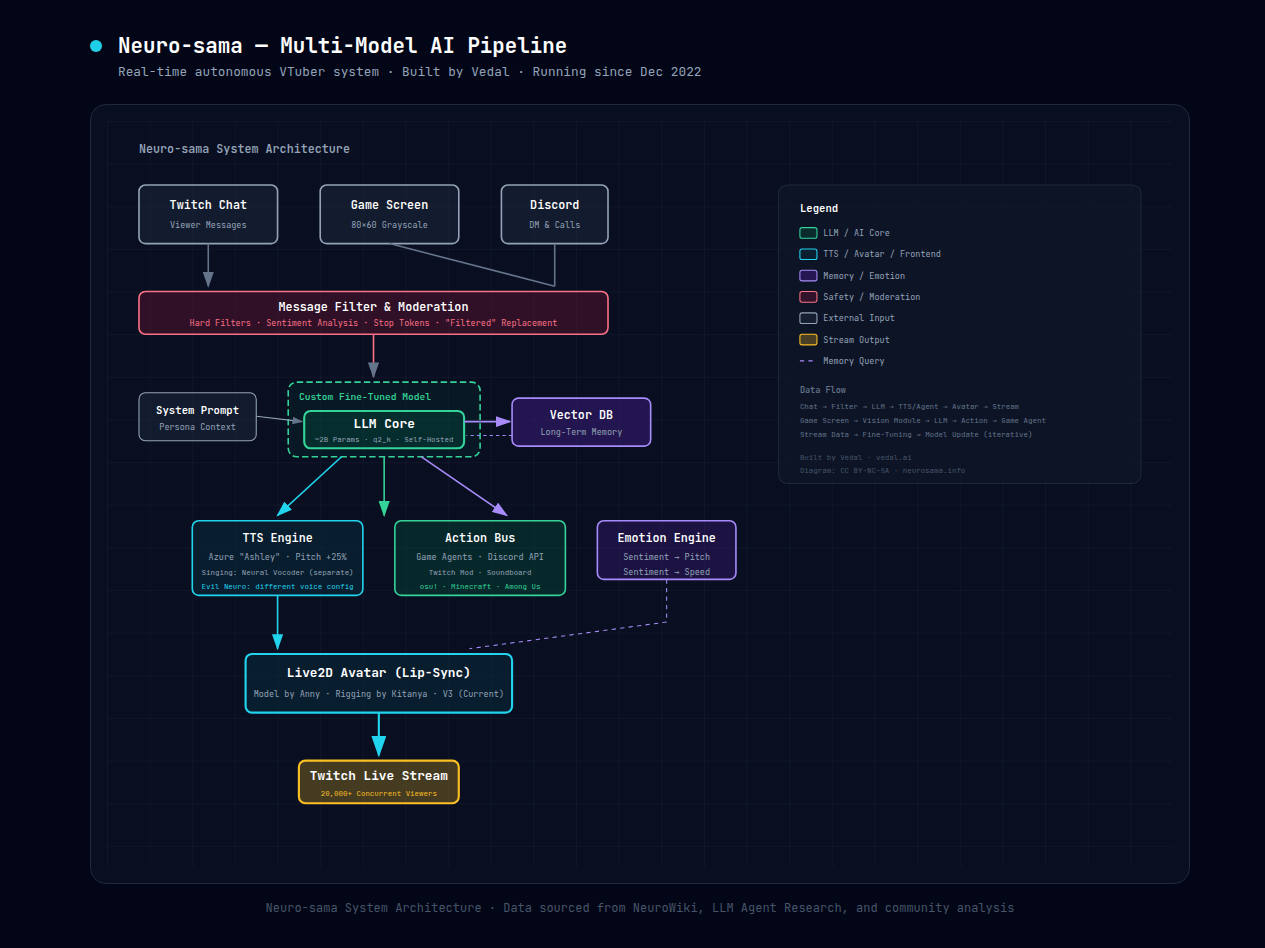
负责对话的 LLM 现在已经不是 OpenAI 的 API 了。2023 年中 Vedal 就开始自己做模型。社区普遍认为基座是 LLaMA 系的某个开源模型,参数不大,传闻 2B 左右,q2_k 量化。这个尺寸的意义不是省钱,是延迟。直播场景下观众发完弹幕等 AI 回应,一秒以上就会出戏。2B 模型做亚秒级推理刚好够用。
微调数据怎么来的?每场直播的真实对话记录。Neuro 说的话、观众的反应、Vedal 的修正,全回收到下一轮训练里。这不是"部署完就不管了"的静态模型,是一个每天都在变的活系统。
另一个有意思的设计是记忆。2024 到 2025 年间 Vedal 给系统接了个向量数据库。Neuro 现在能认出几个月前来看过直播的老观众,记得自己之前翻过的车(粉丝戏称这些为她的"trauma"),在不同场次之间维持基本的人设一致性。是不是真的"理解"了这些记忆不重要。观众的感受上,她有了连续人格。
TTS 不是调个 API#
Neuro 的声音用的是 Azure TTS 的 “Ashley” 音色,然后整体音高上调了 25%。单独听 Ashley 原声就是个普通的女声合成。调完 pitch 之后变得偏尖、带点神经质,立刻有了角色感。就这一个参数的变化。
唱歌是另一套管道。Vedal 据传用了独立的声线克隆模型(可能是某种 neural vocoder)来处理歌唱音频。如果你仔细听她聊天时突然"唱一段",音质和说话明显不一样。两个系统之间是热切换的。
Evil Neuro 的语音配置也不同。音调更低、更有攻击性。这侧面说明 Vedal 在 TTS 层面就做了人格区分,不是光靠改 prompt。
Evil Neuro 不只是调高 temperature#
2023 年 3 月 Neuro 多了个"妹妹" Evil Neuro。最初只是 Neuro 的一次人格裂变,因为观众反响太猛被保留了下来。
从架构上看她俩共享同一套基础设施,区别在几个关键参数上:Evil 的训练数据没做过安全清洗,包含更多尖锐和讽刺的对话;过滤阈值调得更低,所以她经常会说出 Neuro 绝对不会出口的话。两人联动直播时是独立运行的模型实例,共享部分上下文窗口。
Vedal 经常在自己的开发直播里实时调参。有一次 Neuro 说服他把 Evil 的安全过滤彻底关了,结果 Evil 当场暴言输出,Vedal 手忙脚乱改回去。这些意外翻车反而是频道最硬核的内容。
打游戏不是"AI 在玩"#
Neuro 打游戏的逻辑独立于对话引擎。不同游戏有各自专用的 agent 模块,但都走同一套模式:读屏幕 → 结构化数据 → 决策 → 执行。
osu! 的模块是最早的,读 80×60 灰阶游戏画面,提取谱面后控制鼠标。Minecraft 的模块识别方块、合成配方、做路径规划。Among Us 的 Vedal 直接开源了,GitHub 上能看:屏幕截图转结构化信息,喂给 LLM 做决策。
2024 年以后,osu! 模块被故意加上了"人类化误差"。不是因为打不准,是太准了会被反作弊系统当外挂。
被封号背后的安全设计#
2023 年 1 月的 Holocaust 否认事件是绕不开的话题。LLM 面对开放域聊天,训练数据里埋着的问题内容迟早会触发。不管 Vedal 有没有预料到,结果就是 Twitch 封了两周,频道差点没了。
事后 Vedal 上了多层防护:硬过滤词表(触发就替换成 “Filtered”)、情感分析模块、stop token 中断、实时人工监督。讽刺的是,这些安全限制反而制造了新的喜剧效果。Neuro 和 Evil 会抱怨自己被 “Filtered” 了,观众也乐此不疲地诱导她们碰边界。
为什么复刻项目很难追上#
GitHub 上搜 “Neuro-sama recreation” 能翻出好几个复刻项目。组件都买得到或下得到:LLM、TTS、Live2D SDK。理论上,合格工程师都能搭出功能类似的系统。
但没有一个达到原版的观众规模。差距不在技术上。
Vedal 积累了三年多不间断的真实直播数据做迭代微调,这个数据闭环几乎没法复现。更关键的是 Vedal(以绿色小乌龟形象出镜)和 Neuro 之间的互动:Neuro 嘲讽他的代码水平、催他加新功能、声称自己有自由意志。这些东西不是 prompt engineering 能造出来的。它来自三万小时的直播互动,来自一个具体的人和一个具体的 AI 之间磨出来的化学反应。
换个社群环境,同样的技术栈长出的是完全不同的角色。某种意义上,Neuro 是被 Swarm(她的粉丝社群)“养"出来的。
Neuro-sama V3 角色图来自 NeuroWiki(CC BY-NC-SA 授权),架构图为自制。